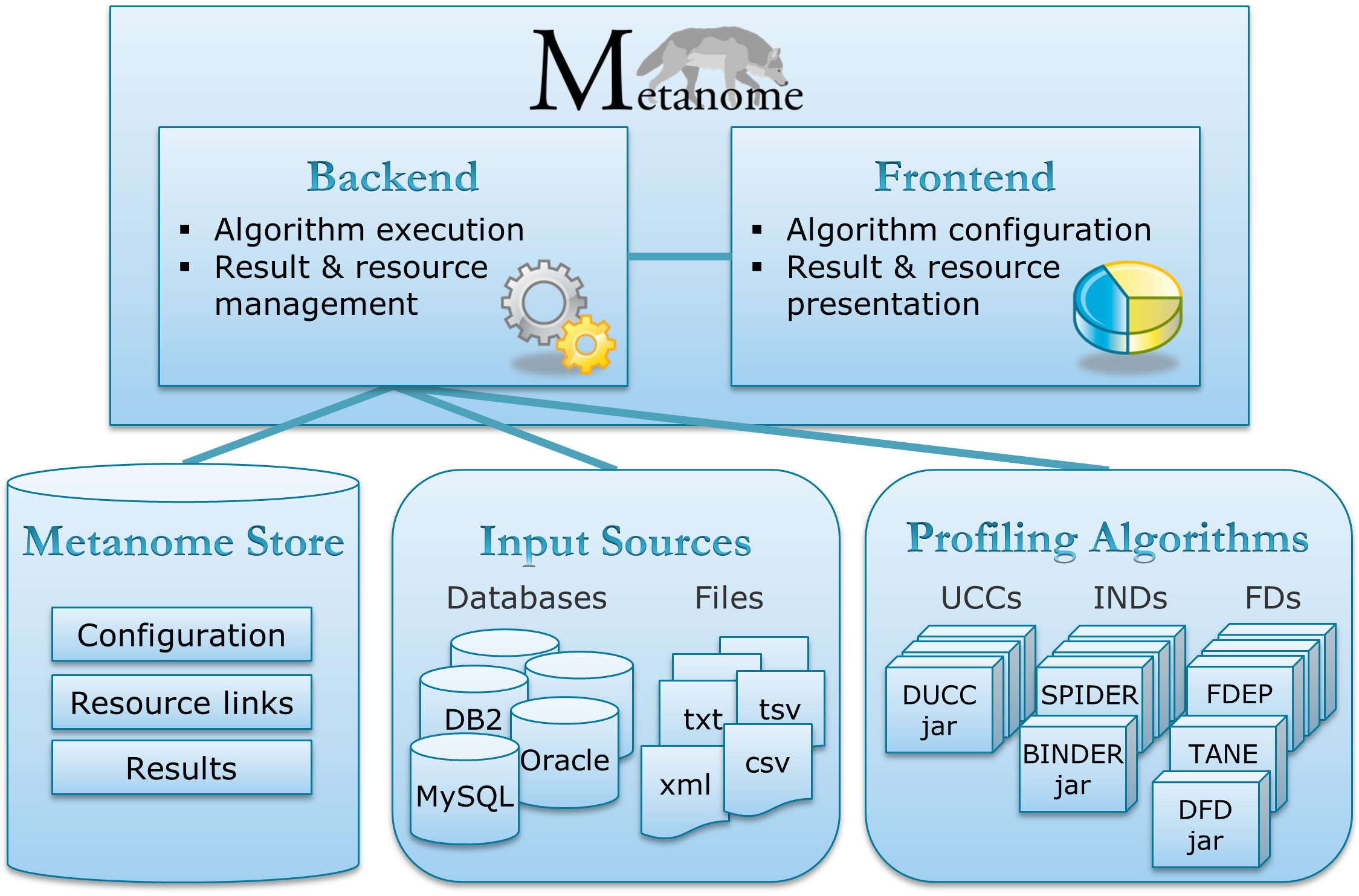
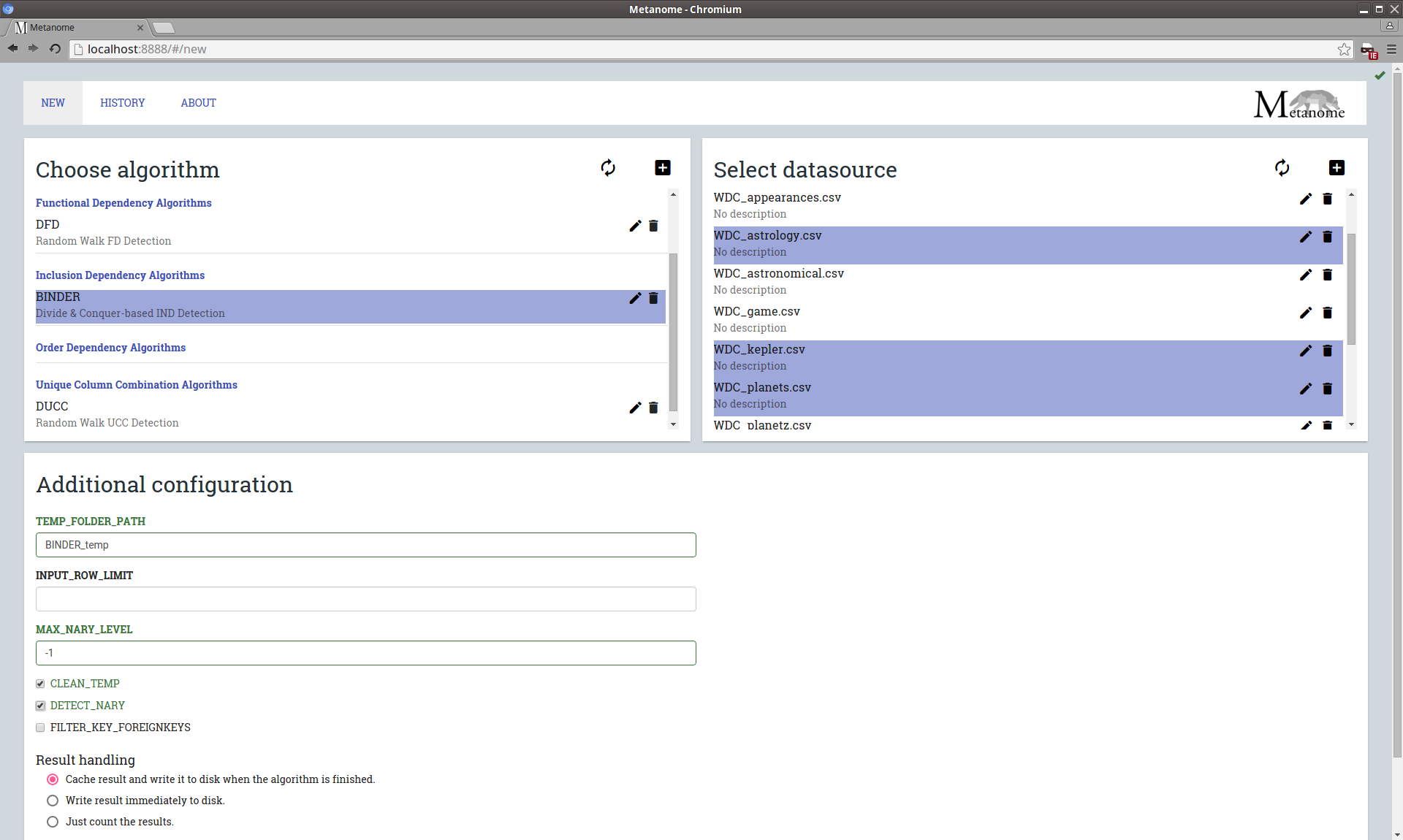
In the context of the Metanome data profiling project, we developed and re-implemented the following profiling algorithms. To run a profiling algorithm, place the according jar-file into the folder /WEB-INF/classes/algorithms and register it in the Metanome frontend. If you want to write your own profiling algorithm for the Metanome tool, we recommend this Skeleton Project to start your development.
The source code for these algorithms is also available on GitHub.
Unique Column Combination (Key Discovery)
Inclusion Dependency (Foreign-Key Discovery) repeatability page
- BINDER (v0.0.2, v1.0, v1.1, v1.2)
- BINDER Database (v0.0.2, v1.0, v1.1, v1.2)
- SPIDER (v0.0.2, v1.0, v1.1, v1.2)
- SPIDER Database (v0.0.2, v1.0, v1.1, v1.2)
- MANY (v0.0.2, v1.0, v1.1, v1.2)
- FAIDA (v0.0.2, v1.0, v1.1, v1.2) (approximate)
Functional Dependencies (Normalization) repeatability page
- HyFD (v1.1, v1.2)
- DFD (v0.0.2, v1.0, v1.1, v1.2)
- Tane (v0.0.2, v1.0, v1.1, v1.2)
- Fun (v0.0.2, v1.0, v1.1, v1.2)
- fdep (v0.0.2, v1.0, v1.1, v1.2)
- FastFDs (v0.0.2, v1.0, v1.1, v1.2)
- FdMine (v0.0.2, v1.0, v1.1, v1.2)
- DepMiner (v0.0.2, v1.0, v1.1, v1.2)
- AIDFD (v0.0.2, v1.0, v1.1, v1.2) (approximate)
- CFDFinder (v1.1, v1.2) (conditional)
Matching Dependencies (Data Cleaning) repeatability page
Multivalued Dependencies (Normalization)
Order Dependencies (Data Ordering)repeatability page
Denial Constraints (Data Cleaning) repeatability page
Complement Dependencies(Data Cleaning)
Basic Statistics (Data Exploration)
Cardinality Estimation (Zeroth-frequency moment of dataset) repeatability page
- FM (v1.1, v1.2)
- PCSA (v1.1, v1.2)
- LC (v1.1, v1.2)
- AMS (v1.1, v1.2)
- BJKST (v1.1, v1.2)
- LogLog (v1.1, v1.2)
- SuperLogLog (v1.1, v1.2)
- MinCount (v1.1, v1.2)
- AKMV (v1.1, v1.2)
- HyperLogLog (v1.1, v1.2)
- Bloom filter (v1.1, v1.2)
- HyperLogLog++ (v1.1, v1.2)
Schema Normalization
- Normalize (v1.1, v1.2) (Boyce-Codd Normal Form)