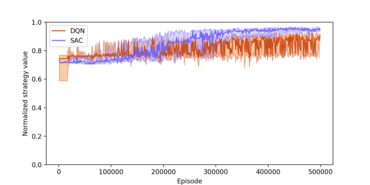
Usage of RL for Revenue Management
In the past, we applied generalistic RL algorithms for problems specified in revenue management. For those experiments, we focused on dynamic pricing, in which the agent has to correctly determine the price choice for a product that maximizes long-term revenue given the current competitor prices. We have shown that the generality of algorithms like Deep Q-Networks (DQN) and Soft Actor-Critic (SAC) allow their application on very broad market setups. We evaluated if and under which conditions those systems do find near-optimal policies in duopolies in many market setups with different competitor strategies. While there are edge-cases in which the systems struggle to find well-performing policies, for example, situations in which the competitor relies on fixed price strategies, they usually show the expected performance. We have observed that the more complex actor-critic systems tend to show better performance than their value estimation-based counterparts, represented by DQN. The analysis displayed a noticeable disadvantage of the systems, which lies in the number of required observations until convergence. SAC did achieve convergence after more than 100,000 observations to yield a near-optimal policy reliably. The following research projects aim at overcoming this limitation. Furthermore, we observed that convergence in a duopoly is hard to achieve when both competitors do use self-adjusting policies, a problem that we try to overcome with asymmetric information in multi-agent pricing problems.
Transfer Learning for Revenue Management
Transfer learning formalizes the idea, that the convergence speed of an algorithm can be improved by using data sourced from multiple problems. There is a magnitude of alternatives assessed by current RL research projects, which consist of very different mechanisms to achieve this goal. Training one conventional agent with information sourced from several different MDPs is difficult. Different state and action spaces have to be encoded in a way, that a single parametric function can evaluate them and output a meaningful response. While this includes formal equality of the state- and action spaces, this also requires equality of the state-transition and reward function. In this sense, equality means that performing the same action in the same state leads to the same result in all processes. Having equal state- and action spaces and equal state-transition and reward probabilities violates the concept of having multiple different problems to source data. Several proposals have been made by available literature to solve this discrepancy. As an example, we use DISTRAL, an algorithm that uses a multi-policy approach to improve information exchange. In DISTRAL, a different policy is optimized for each problem used to generate data. The information exchange occurs by regularizing the policies to move towards a distilled policy, which in turn is generated by searching for the policy that achieves minimal divergence from all task-specific policies. This algorithm still requires a formally equal state and action space, but each task-specific policy can take different transition and reward mechanics into account.
For revenue management, in many cases, formal equality is not given as well. For different products, possible price choices and reasonable state descriptions do deviate. We propose to dynamically map those different price areas and market states into a single unified representation and then use DISTRAL to learn unified policies under minimal policy deviations necessary. This approach combines several of the proposed mechanisms for multi-task reinforcement learning. Given the specialized nature of the problem under evaluation, we expect further improvements to be possible if the generality of the parametric representation functions is given up to reduce the search space and allow usage of joint layers between the task-specific policies.
Multi-Agent Systems with Non-Symmetric Knowledge
Past research has shown that it is hard to achieve stable equilibria with multiple reinforcement learning-based agents in the same system, especially if they rely on non-linear function approximation tools. The independent updates of the agents' policy dramatically increase the difficulty, as each algorithm has to keep up with policy changes, which in turn changes its policy. In the past, several publications evaluated markets with non-symmetric information and achieved convergence under those conditions. In such a market, one agent has access to all other agents' current policies and can incorporate this information in its learning mechanism by evaluating the expected reward given the competitors' reaction. Previously, such systems were mostly used with RL algorithms that use tabular representations of the value functions. This project aims at evaluating if such a system achieves convergence when used with non-linear function approximation tools. Furthermore, the structural properties of the process have to be considered. In practice, a competitor lacks the motivation to publish his policy, as this leaves the leader of the game with an advantage. We currently plan to measure if the faster convergence can lead to improvements for every market participant which prevails the disadvantage of having to publish his current policy. If this is not the case, equality can be achieved by allowing each market participant to charge a fee. The correct amount of this fee has in turn to be estimated correctly to achieve equal gains by information exchange, an additional optimization problem that has to be solved in the future.
State Space Exploration
In most RL systems, exploration is purely stochastic and action-based. In Q-learning with e-greedy policies, an action is chosen randomly given the current state. Systems like Soft Actor-Critic encode randomness in their state-dependent policies. In the future, we propose to improve this mechanism by allowing state-space-oriented exploration. We aim at finding a mechanism, which allows an agent to recognize areas of the state space he observed regularly and those areas which have been rarely seen in the past. If the agent does know state-transition probabilities, this can be achieved by recognizing the confidence for each observed state, measured by the number of visits in a discrete state space, and explicitly aim for those states which have been rarely observed. The formal requirement of knowledge about the state transitions makes this approach only suitable for methods like Approximate Dynamic Programming. For systems without knowledge about transition probabilities, a different method has to be found. For Q-learning, exploration counts can be recorded together with the Q-values themselves, an approach that might make this method suitable for further evaluation.
Outlook
While we are currently evaluating several improvements regarding both multi-task and multi-agent setups, which we both deem necessary to allow usage of RL systems in practice, further research in this area is possible and necessary. While all extensions described are currently under evaluation, several new improvements for reinforcement learning stay unused. This includes model-based reinforcement learning, which keeps a model to learn state transitions and alternatives to replace DISTRAL, which rely on other information exchange methods than policy exchange. Furthermore, there are examples of RL algorithms which avoid the use of deep models, which displays an interesting alternative, as the current models are not interpretable by their users.