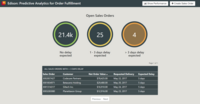
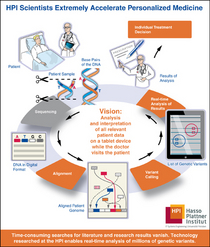
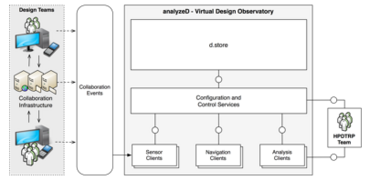
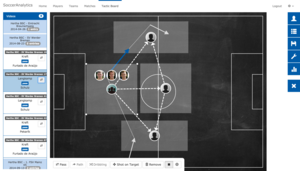
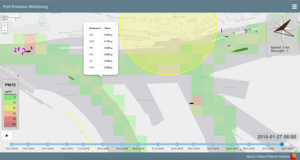
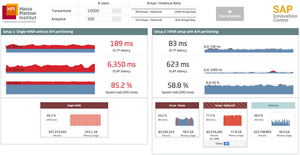
The ever increasing amount of data that is produced nowadays, from smart homes to smart factories, gives rise to completely new challenges and opportunities. Terms like "Internet of Things" (IoT) and "Big Data" have gained traction to describe the creation and analysis of these new data masses. New technologies were developed that are able to handle and analyze data streams, i.e., data arriving with high frequency and in large volume.In recent years, e.g., a lot of distributed Data Stream Processing Systems were developed, whose usage represents one way of analyzing data streams.
Although a broad variety of systems or system architectures is generally a good thing, the bigger the choice, the harder it is to choose. Benchmarking is a common and proven approach to identify the best system for a specific set of needs. However, currently, no satisfying benchmark for modern data stream processing architectures exists. Particularly when an enterprise context, i.e., where data streams have to be combined with historical and transactional data, existing benchmarks have shortcomings. The Enterprise Streaming Benchmark (ESB), which is to be developed, will attempt to tackle this issue. Read more.
Contacts: Guenter Hesse
Research Area: Enterprise Software Engineering