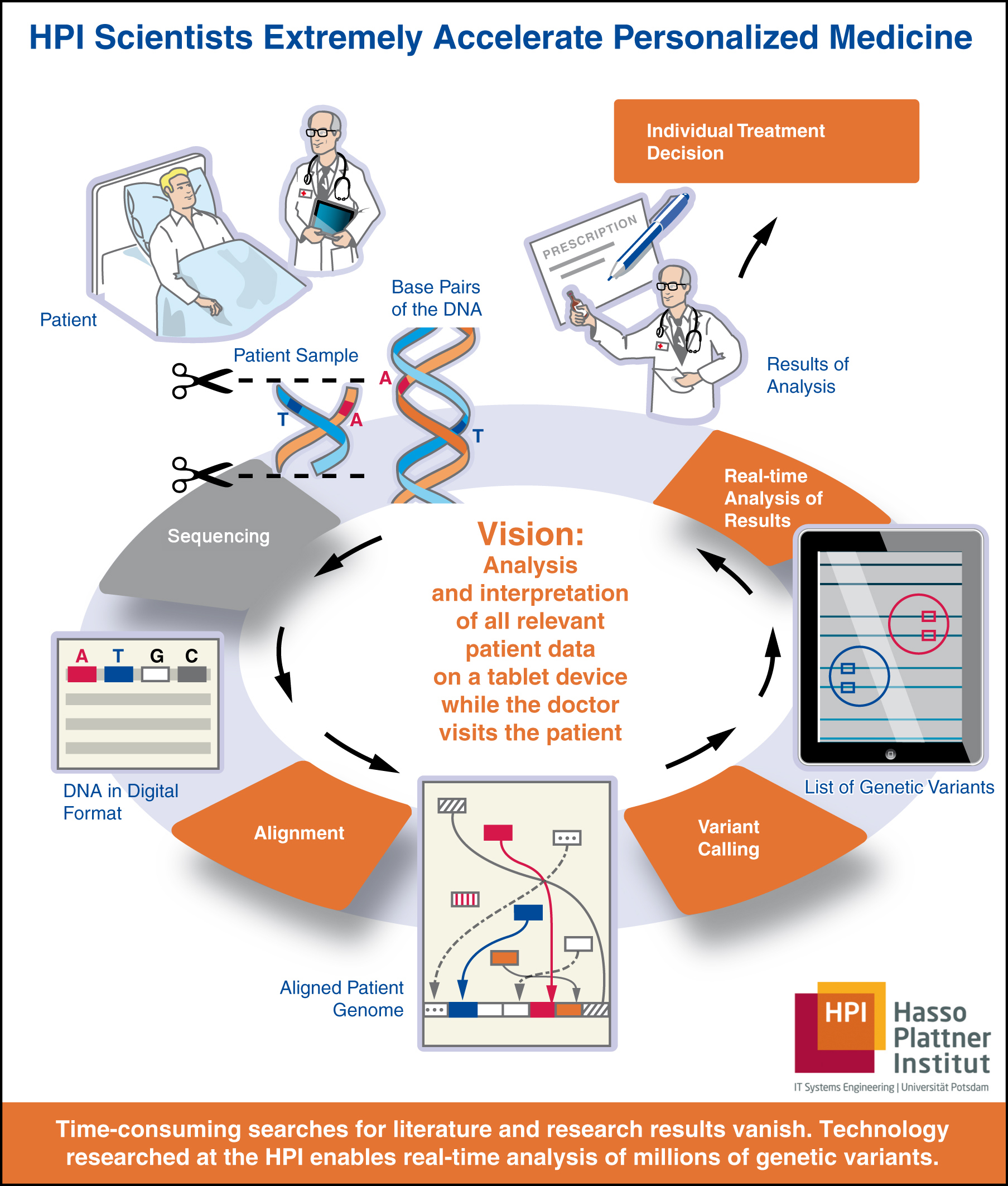
The continuous progress in understanding relevant genomic basics, e.g. for treatment of cancer patients, collides with the tremendous amount of data, that need to be processed. For example, the human genome consists of approx. 3.2 billion base pairs resp. 3.2 GB of data. Identifying a concrete sequence of 20 base pairs within the genome takes hours to days if performed manually. Processing and analyzing genomic data is a challenge for medical and biological research that delays progress of research projects. From a software engineering point of view, improving the analysis of genomic data is both a concrete research and engineering challenge. Combining knowledge of in-memory technology and of how to perform real-time analysis of huge amount of data with concrete research questions of medical and biological experts is the aim of the HIG project. The project was initiated in the spring 2012 in response to the overwhelming feedback about the first results of the HANA Oncolyzer project.