We analyze loaded files at three levels.
- Header: we consider a header to be loaded correctly, if the output files it contains all and only the columns of the input file.
- Record: since relational tables are not order-sensitive with respect to records, but columns are ordered, we consider records to be equal if they contains the same values in the same order.
- Cell: at the cell level, we do not consider record or column order, but consider two cells to be equal if their content is the same.
For every level we evaluate precision, recall, and F1-score comparing the input and the output of the loading. Additionally, we include the "success" measure, a binary measure of whether the system was able to load the file in memory.
The final benchmark score is obtained as the average of these scores across the original input file and the 2289 polluted versions of it, and finally sum across different scores.
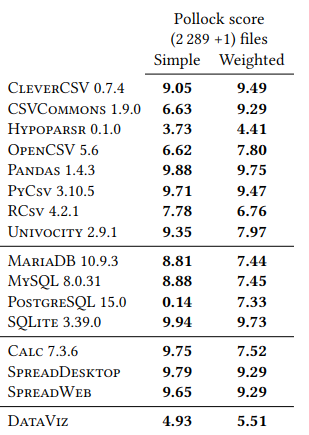
As all the scores are in the range [0,1] with 1 being the hightest possible, the maximum score obtainable by a given system is 10.
We experiment with two weighting schemes for the average: a "simple" average, giving a weight of one to every polluted file, and a "weighted" average giving a weight to each polluted file depending on the frequency of the pollution in our real-world survey.
We used our benchmark to evaluate sixteen different real-world systems in four categories:
- CSV parsing module from three different languages: CleverCSV, Pandas, and the standard library parser for Python; OpenCSV, Univocity, and CSVCommons for Java; Hypoparser and the standard library parser for R.
- Relational databases: MariaDB, MySQL, PostgreSQL and SQLite.
- Spreadsheet software: LibreOffice Calc, a commercial software defined as SpreadDesktop, and a web-based software defined as SpreadWeb (real names omitted due to licensing).
- Business intelligence tools: a commercial tool defined as DataViz (real name omitted due to licensing).
The results of sixteen different real-world systems on the Pollock benchmark can be seen in the table below: