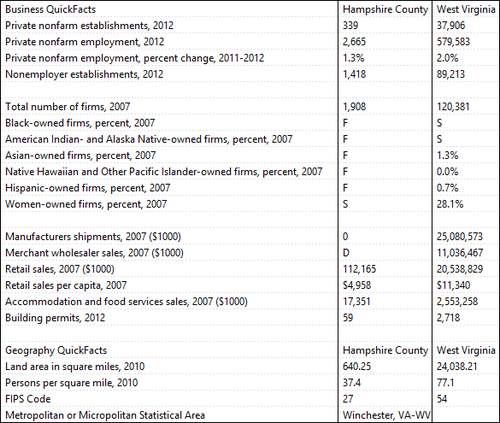
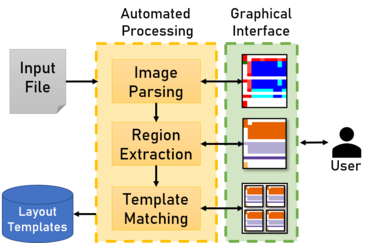
The intuition of Mondrian [1] is parsing spreadsheets as images to inspect their visual properties and search for multiple data regions.
The goal is to identify multiregion templates, i.e., file layouts that occur in multiple files.
First, the cells of a spreadsheet are converted into pixels, encoded with different colors, such that cells with similar syntax share similar colors (e.g., integer numbers are dark blue and floating point numbers are light blue, while strings are red).
Then, Mondrian detects multiple regions, partitioning the image into groups of adjacent pixels and clustering them together to form regions.
For each of the extracted regions, Mondrian calculates a "fingerprint" which describes its syntactic and structural properties and it can be used to compare regions across different files. Files that show at least one similar region are more probable to share the same layout, therefore are selected as candidates instances of the same template.
Each file layout is then described with a connected graphs that encodes the information about the regions that it contains and their connectivity (i.e., how they are arranged relative to each other in the spreadsheet). Finally, using a graph similarity score, we measure the similarity between file layouts that had similar regions.