Alphabetical Sorting of Authors
Felix Naumann, August 24, 2010
In computer sciences a typical ordering of co-authors of a publication is alphabetical, unless there is a good reason to deviate from this order (for instance if some authors contributed considerably more than others). However, the actual ordering does become interesting for instance for graduating PhD students or professors up for tenure. Committees do consider the number of publications in which the candidate is in fact the first author.
The hypothesis that I want to verify (or better reject) is the following:
Researchers with last names that appear earlier in the alphabet have a career advantage.
Or in other words: Does alphabetical sorting of authors give unfair advantage to researchers like Til Aach? Here, I measured career advantage simply by counting publications. The reasoning was that researchers with alphabetically early names are promoted more often, obtain more funds, etc., and thus are more successful in their research. I deliberately ignored other measures such as counting citations.
I checked this hypothesis using a 2009 DBLP data set provided by Hannah Bast. The most tricky part was to identify the first letter of the last name, because names were stored in full as in “Philip A. Bernstein”. My (still crude) approach is the following SQL query, which simply checks for the existance of a middle initial. If the author name has such an initial, the first letter after the initial is chosen, if not the first letter after the first space character is chosen:
SELECT PUBID, AUTHOR,
CASE WHEN
LOCATE(‘.’, AUTHOR) = 0 OR LOCATE(‘Jr.’,AUTHOR) > 0 OR LOCATE(‘Sr.’,AUTHOR) > 0 OR LOCATE(‘.’, AUTHOR) = LENGTH(AUTHOR)
THEN
SUBSTR(UPPER(AUTHOR),POSSTR(AUTHOR,’ ‘)+1,1)
ELSE
SUBSTR(UPPER(AUTHOR),LOCATE(‘.’, AUTHOR)+2,1)
END AS INITIAL,
EDITOR, AUTHOR_NUM
FROM DBLPAUTHORS
Obviously, this could be greatly improved. Approximately 1100 extracted letters were not among the letters A-Z. In addition, for researchers with a full middle name in DBLP, that middle name is “mistaken” for the last name. Other sources of error are persons with multiple middle initials and authors with only an initial as the first part of a name.
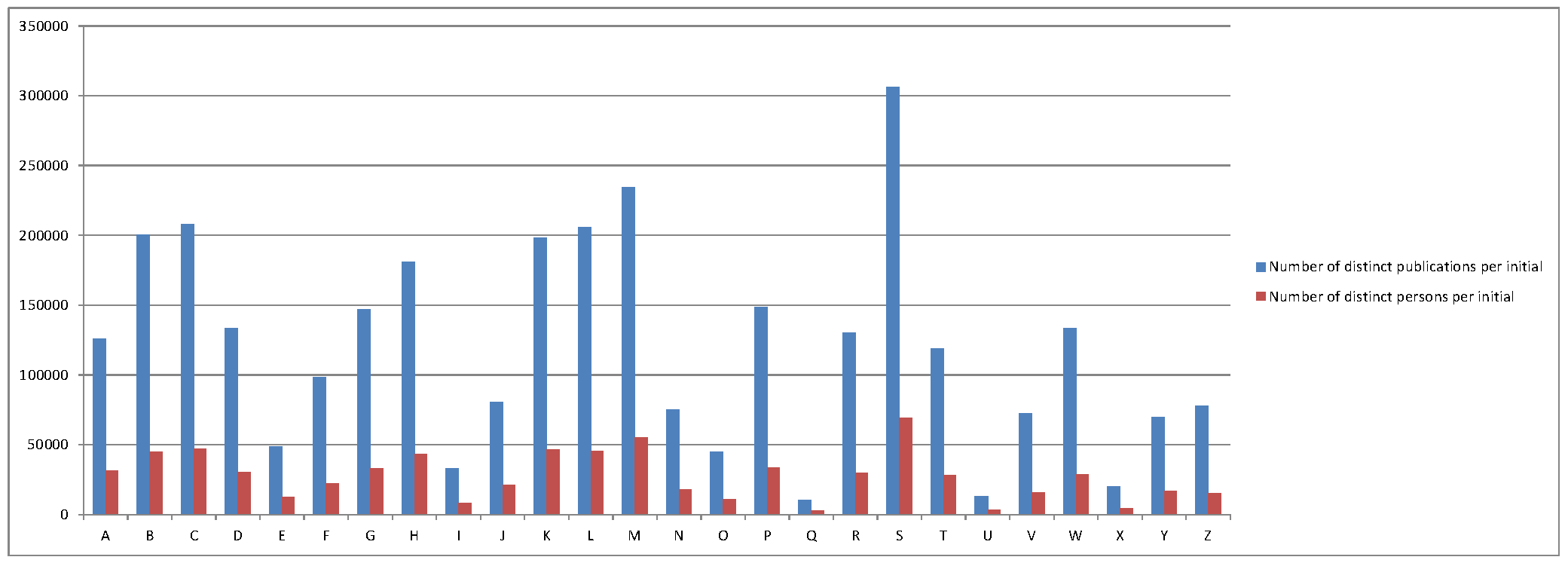
Next, I calculated the number of distinct publications per initial and the number of distinct persons for normalization:
SELECT DISTINCT AUTHOR, INITIAL FROM
( … view … )
ORDER BY AUTHOR
SELECT INITIAL , COUNT(*) AS ANZ
FROM
(SELECT DISTINCT AUTHOR, INITIAL FROM
(… view …)
)
GROUP BY INITIAL
ORDER BY INITIAL
The results can be seen here:
Graphic
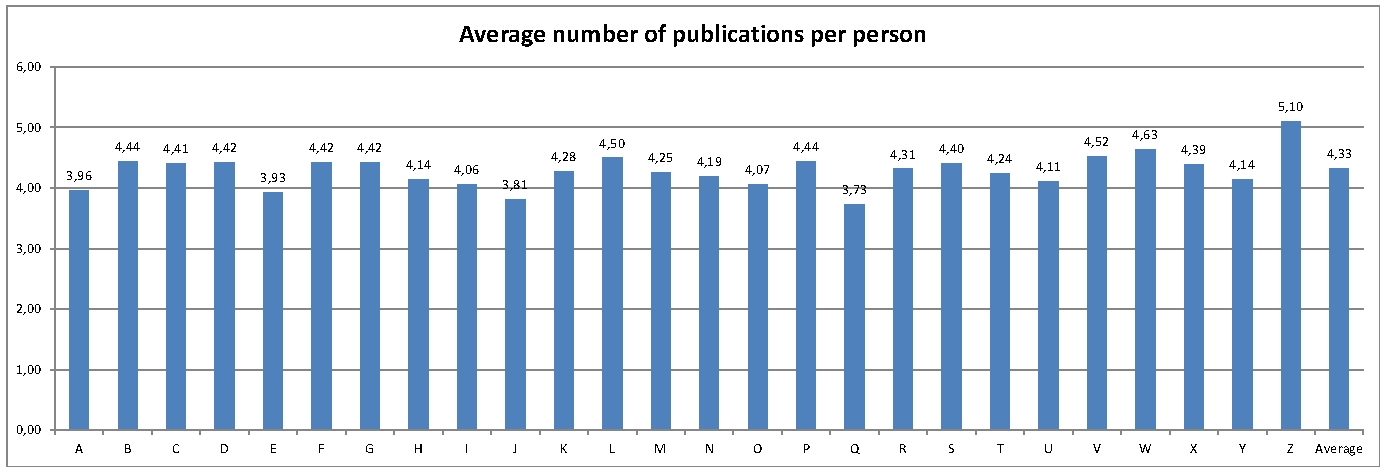
Finally, I calculated the average number of publications per person and letter:
Graphic
In conclusion, we can clearly reject the hypothesis. In fact, having a last name starting with Z is apparently of great advantage.
Future work must certainly include a better parsing of the name attributes. If someone has a version of DBLP with names separated into individual fields I would gladly include those. In addition, measuring success as the number of publications is certainly not satisfactory. Counting citations might be a good (but more difficult to correctly implement) alternative.

{kind=link}
{kind=link}