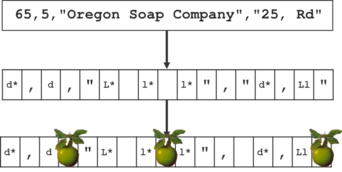
Data is often encoded, distributed, and stored in data files. To access the content of these files, it is necessary to parse their structure. For some formats, file structure is well defined with strict standards: JSON, XML, etc..
For others, such as CSV and CSV-like files, structure is more loosely defined and it is often the result of custom decisions and ad-hoc adaptation to the RFC standard to fit a given use case. Therefore, users are often required to know the structure beforehand, for example to parse delimiters and quotation characters, remove possible comment or metadata lines, extract multiple tables etc. etc.
These tasks are all necessary steps required at the syntactical level, preparing the data file in order to properly loading its content and perform semantic tasks, whether further cleaning or downstream tasks.
Currently, structural data preparation is the elephant in the room. Every data practictioner has to deal with stuctural issues, yet little attention is devoted to making these efforts systematic, documented, or reproducible.
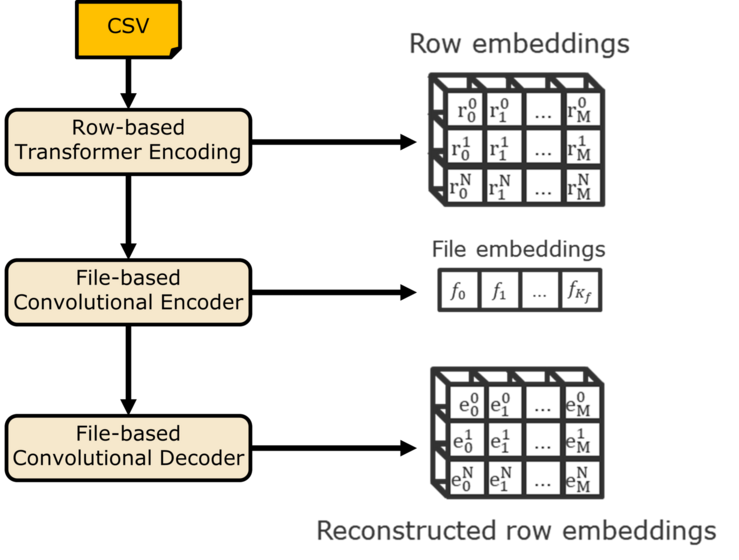
As a foundational step towards systematic data preparation, we envision an unamiguous representation for the structure of files, that could be used to automate different structural tasks, to assess the level of preparation necessary in order to load a given dataset, or as metadata for structural indexing of data files.
To serve these purposes we propose MaGRiTTE: an Machine Generated Representation of Tabular files using Transformer Encodings.