AggreCol
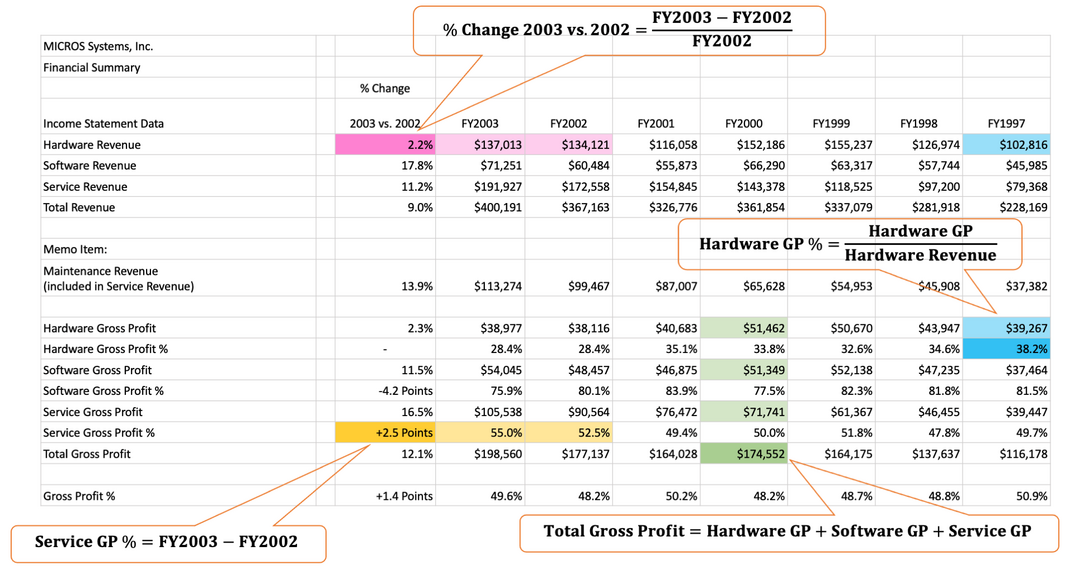
Aggregations are an arithmetic relationship between a single number and a set of numbers. Tables in raw CSV files often include various types of aggregations to summarize data therein. Identifying such metadata in tables can help understand file structures, detect and repair data errors, and normalize tables. However, recognizing aggregations in CSV files is not trivial, as these files often organize information in an ad-hoc manner with aggregations appearing in arbitrary shapes and positions and displaying rounding errors. The Figure below demonstrates an example of verbose CSV files with various aggregations.
AggreCol
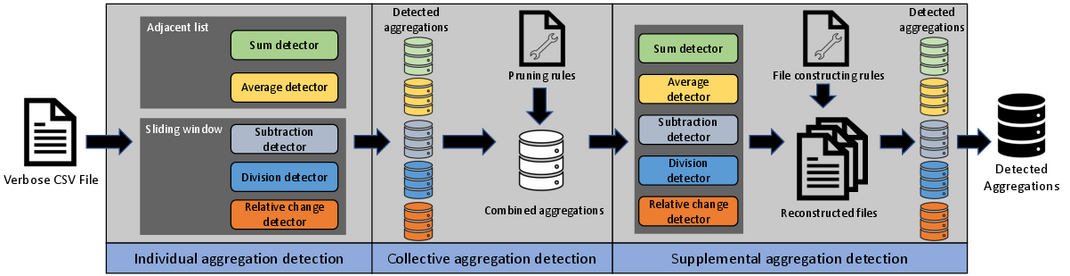
We propose a three-stage approach AggreCol to automatically detect various types of aggregations in verbose CSV files. Our approach supports sum, difference, average, division, and relative change. In the first stage, AggreCol detects adjacent aggregations of each function separately. An aggregation is adjacent if the set of cells in its range are adjacent to its aggregate. The second stage collects the individual detection results and removes the spurious aggregations with a set of pruning rules. In the last stage, our approach aims at recognizing non-adjacent aggregations by skipping the aggregates of detected aggregations.
Resources
Datasets
Here we list the datasets and their annotations used in our project. Note that due to license issues, only publicly distributable datasets are listed here. Each link points to a compressed json file that includes both the verbose CSV files and their annotations.
The validation dataset comprises files from the Troy and the EUSES datasets, while the unseen dataset comprises files from the SAUS and the CIUS datasets.
| Unseen | 81 | 5,854 | 1000 tables collected from international statistical websited by DocLab graduate students in 2009-2010. This dataset includes 200 sample files of them. |
Code
The source code is now available at Github.
Annotation Tool
Coming soon.
Contact
If you have any questions, please do not hesitate to contact Lan Jiang.