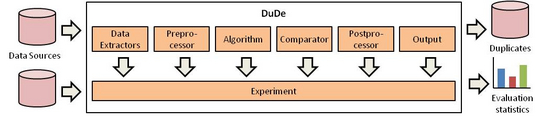
Data Sources
The data source component is used to extract data from any data source that is supported by the toolkit and to convert the data into the internal JSON format. Currently, we are able to extract records from relational databases (Oracle, DB2, MySQL and PostgreSQL), CSV files, XML documents, JSON files, and BibTeX bibliographies. For each data source, a record identifier, consisting of one or many attributes, can be defined and additionally a global ID is assigned to each data source, which is also saved within the extracted records. This allows a comparison of records from different sources without the necessity of an source-wide unique identifier.
Preprocessor
The preprocessor is used to gather statistics while extracting the data, e.g., counting the number of records or (distinct) values. After the extraction phase, each preprocessor instance is accessible within the algorithm and within comparators that need preprocessing information.
Algorithms
Algorithms are responsible for selecting pairs of records from the sources that should be classified as duplicate or non-duplicate. We support all algorithms that follow a pair-wise comparison pattern. Most algorithms require some kind of preprocessing, such as sorting for the Sorted Neighborhood Method or partitioning for the Blocking Method. Therefore, each algorithm can execute a preprocessing step before returning record pairs. In case of sorting, DuDe allows the definition of a sorting key and the selection of a sorter.
Algorithms do not not select all duplicate pairs at once, but rather select a candidate pair that is pipelined to the similarity function and then classified before the next candidate pair is selected. Therefore, it is possible that algorithms get notified whether the former pairs have been classified as duplicate or non-duplicate, before the algorithm selects the next pair. This is neccessary for algorithms that select pairs in dependency to previous classifications.
Similarity Functions
Similarity functions are used to compare two records and calculate a similarity. The similarity is a value between 0 and 1, with 1 defined as equality. We distinguish between three types of comparators:
- Structure-based similarity functions can be used to compare objects based on their structure. This is especially interesting if records from different sources with different schemas are compared (e.g. calculating the similarity based on the number of equal attributes in two records).
- Content-based similarity functions can be used to compare objects based on concrete attribute values. Examples are Levenshtein, SoundEx and identity comparators.
- Aggregating similarity functions (e.g. min, max) can be used to combine different structure- or content-based comparators.
Postprocessor
The postprocessor receives the classified record pairs and performs additional processing: Two important postprocessors are the transitive closure generator and the statistic component. The former calculates the transitive closure for all classified duplicates. The latter allows the calculation of key figures, such as runtime, number of generated record pairs, or number of classified duplicates. If a gold standard exists for a dataset, additionally precision, recall, f-measure, etc. are calculated.
Output
There are several output formats for the record pairs, including a simple text output that writes each result pair into one line using a specified separator for the attribute values, and a JSON output, which uses JSON syntax. The CSV output allows the output of additional information for record pairs, such as the calculated similarity or whether the pair has been classified as duplicate or not. The statistic component has its own CSV output, which also allows the specification of additional attributes. These attributes can be used to describe the configuration of an experiment. All outputs can be written to the screen or into a file. The offered output components can easily be extended to meet experiment specific requirements.