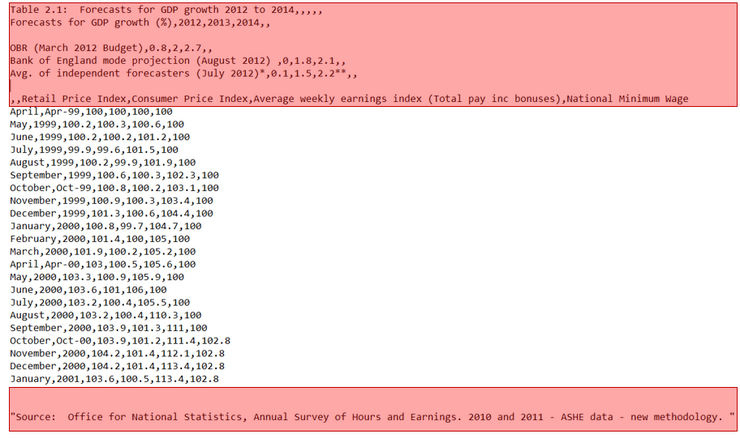
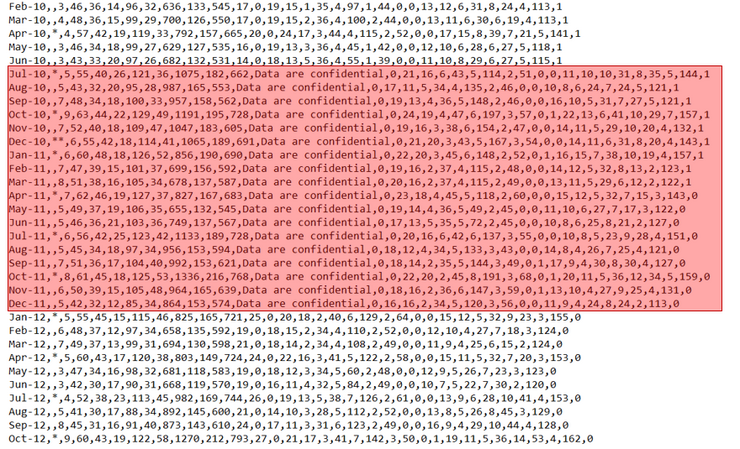
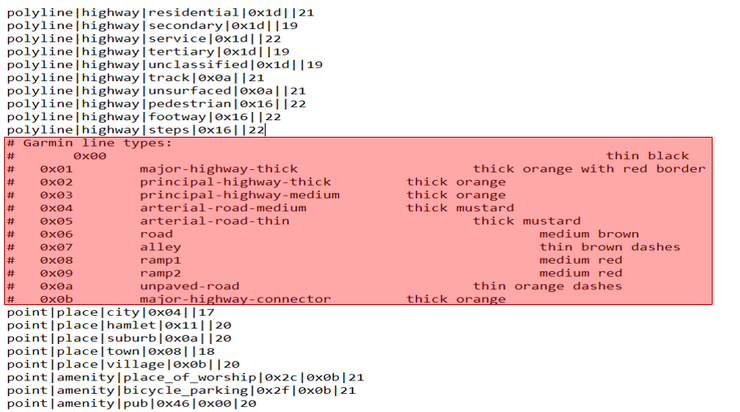
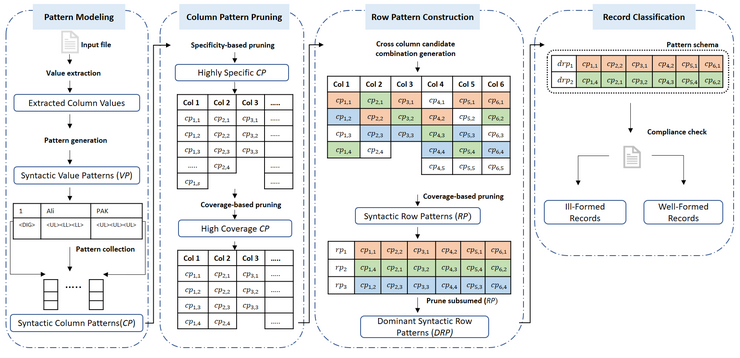
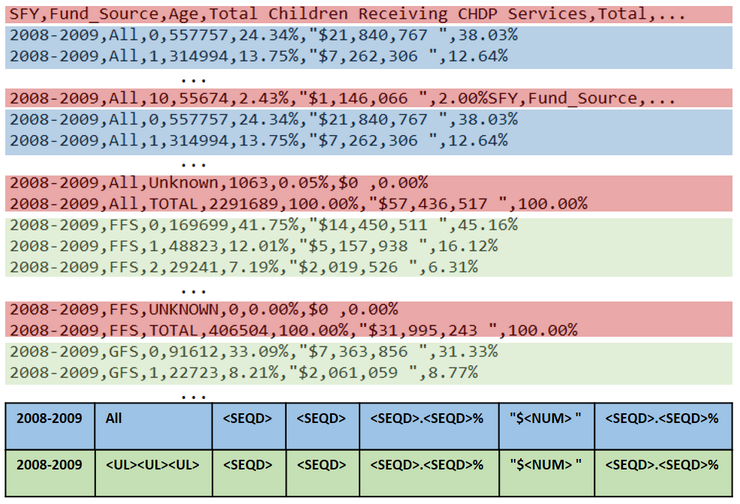
Comma-separated value (CSV) files are one of the most commonly used formats, widely available on most open data portals, and frequently used in scientific projects. Not only can these CSV files be used for exploring, collecting, and integrating data, but their use is also significant in other research areas, such as knowledge-based design, building machine learning models, and information mining.
Despite the existing standard RFC 4180, data entry into CSV files is prone to errors because users and applications do not always ad-here to this standard; moreover, the standard itself is rather loose. This behavior is also present in CSV files available on open data portals. Out of 2066 files randomly selected from a government data portal Data.Gov, we were unable to directly load 418 (20.2%) of them into an RDBMS due to ill-formed records.
Similar to Data.Gov, we crawled data from four other open data portals (Mendeley, GitHub, UKGov, NYCData) and found files with ill formed records. We used files from all five sources in our experiments.