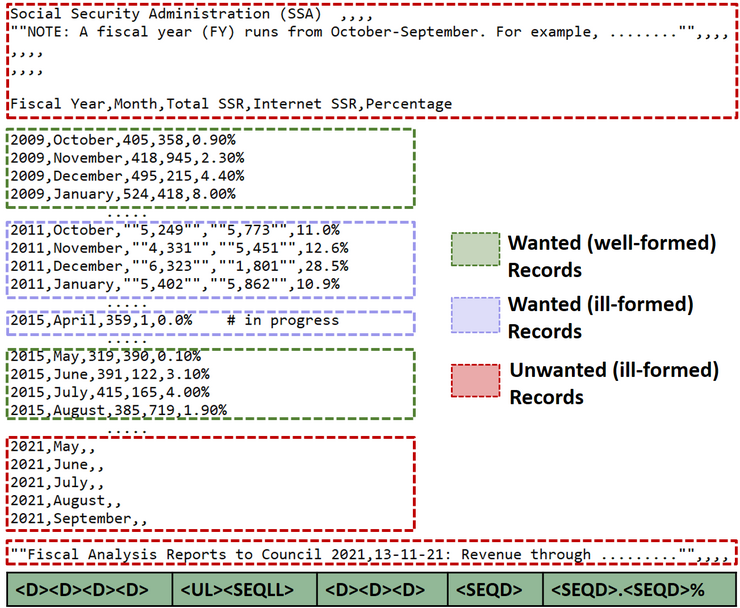
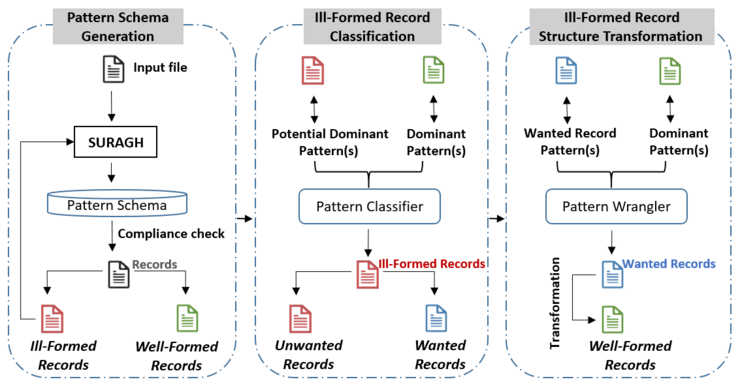
The workflow of TASHEEH consists of three phases. In the first phase, it first uses the output of its predecessor SURAGH to classify input file records as ill-formed or well-formed using dominant row patterns . Then, it runs SURAGH incrementally for ill-formed records to obtain row patterns specifically for those rows; we call these patterns potential dominant row patterns, as these ill-formed data rows can possibly be transformed into well-formed data rows. TASHEEH repeats the incremental pattern generation process until no dominant, ill-formed records are left. After the first phase, TASHEEH obtains dominant and potential dominant patterns for well-formed and ill-formed records, respectively. The second phase uses these patterns to classify ill-formed records into wanted and unwanted. In the final phase, TASHEEH collects wanted records, well-formed records, and their patterns from the previous phase and removes the unwanted records. It then uses the pattern transformation grammar to transform the wanted records into well-formed ones.