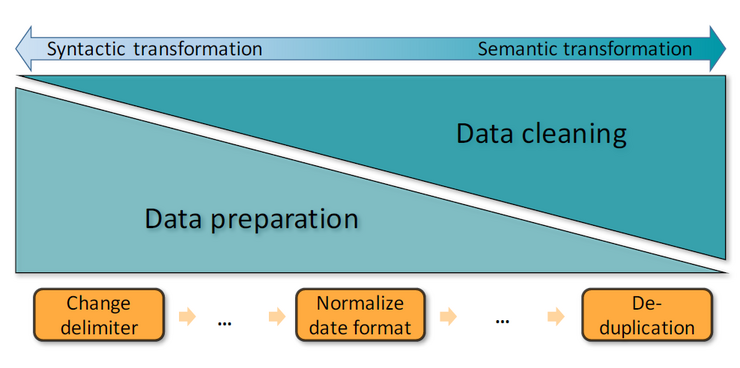
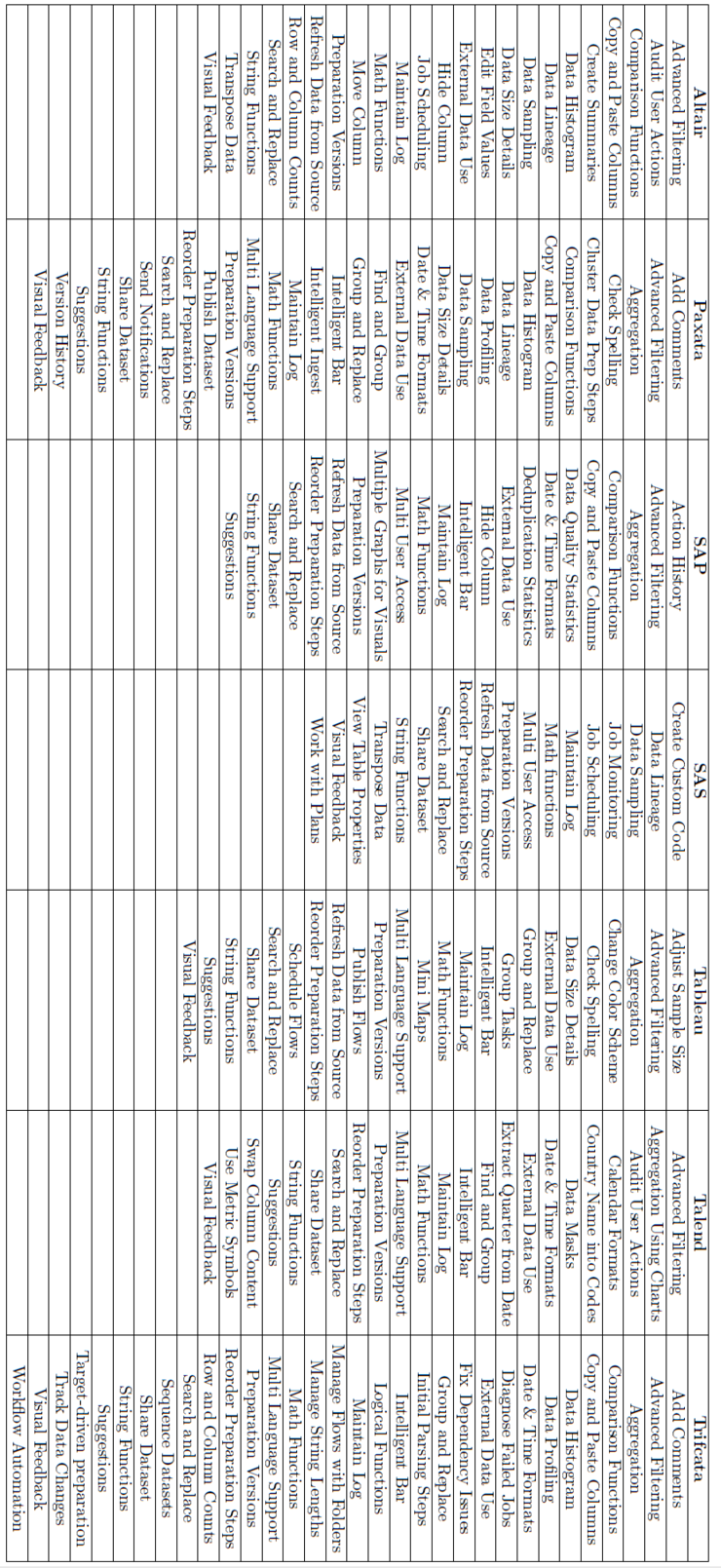
Data preparation is not a single step process. Rather, it usually comprises many individual preparation steps, implemented by what we call preparators, and which we have organized anew into six broader categories, defined here.
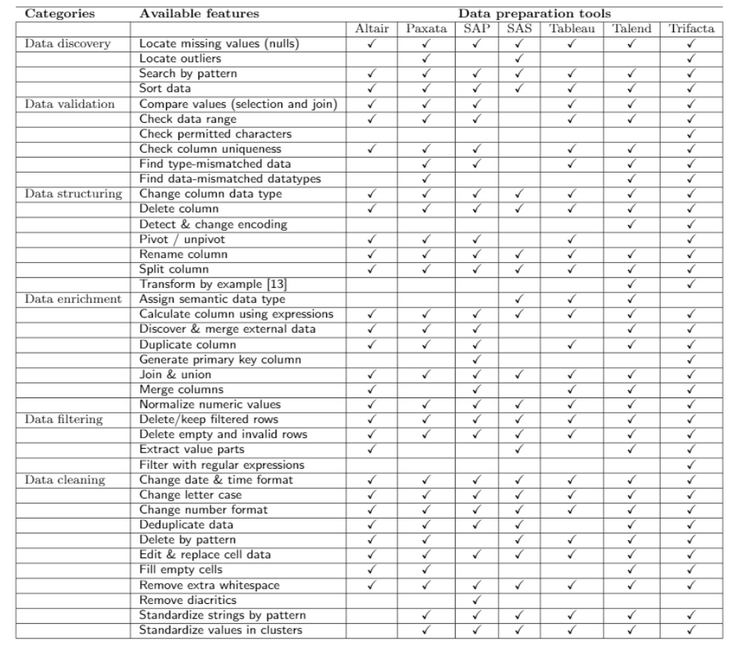
Data discovery is the process of analyzing and collecting data from different sources, for instance to match data patterns, find missing data, and locate outliers.
Data validation comprises rules and constraints to inspect the data, for instance for correctness, completeness, and other data quality constraints.
Data structuring encompasses tasks for the creation, representation and structuring of information. Examples include updating schema, detecting and changing encoding and, transform data by example.
Data enrichment adds value or supplementary information to existing data from separate sources. Typically, it involves augmenting existing data with new or derived data values using data lookups, primary key generation, and inserting metadata.
Data filtering generates a subset of the data under consideration, facilitating manual inspection and removing irregular data rows or values. Examples include extracting text parts, and keeping or deleting filtered rows.
Data cleaning refers to removal, addition, or replacement of less accurate or inaccurate data values with more suitable, accurate or representative values. Typical examples are deduplication, fill missing values, and removing whitespace.
Despite our definition, which distinguishes data preparation and cleaning, we include data cleaning steps here as well, as most data preparation tools also venture into this area.