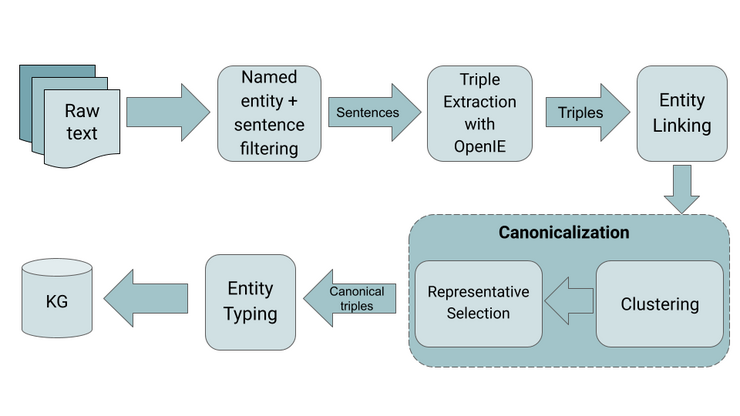
Knowledge Graphs (KGs) are a popular way to structure and represent knowledge in a machine-readable way. While KGs serve as the foundation for many applications, the automatic construction of these KGs from texts is a challenging task where Open Information Extraction techniques are prominently leveraged. In this paper, we focus on generating a domain-specific knowledge graph based on art-historic texts from a digitized text collection. We describe the combined use and adaption of existing open information extraction methods to build an art-historic KG that can facilitate data exploration for domain experts. We discuss the challenges that were faced at each step and present detailed error analysis to identify the limitations of existing methods when working with domain-specific corpora.