Traditional named entity linking (NEL) tools have largely employed a general-domain approach, spanning across various entity types such as persons, organizations, locations, and events in a multitude of contexts. While multimodal entity linking datasets exist (e.g., disambiguation of person names with the help of photographs), there is a need to develop domain-specific resources that represent the unique challenges present in domains like cultural heritage (e.g., stylistic changes through time, diversity of social and political context).
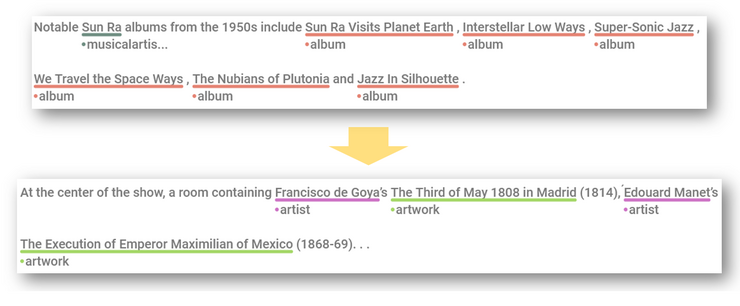
To address this gap, our work presents a novel multimodal entity linking benchmark dataset for the art domain MELArt together with a comprehensive experimental evaluation of existing NEL methods on this new dataset. The dataset encapsulates various entities unique to the art domain. During the dataset creation process, we also adopt manual human evaluation, providing high-quality labels for our dataset. We introduce an automated process that facilitates the generation of this art dataset, harnessing data from multiple sources (Artpedia, Wikidata and Wikimedia Commons) to ensure its reliability and comprehensiveness. Furthermore, our paper delineates best practices for the integration of art datasets, and presents a detailed performance analysis of general-domain entity linking systems, when applied to domain-specific datasets. Through our research, we aim to address the lack of datasets for NEL in the art domain, providing resources for the development of new, more nuanced, and contextually rich entity linking methods in the realm of art and cultural heritage.