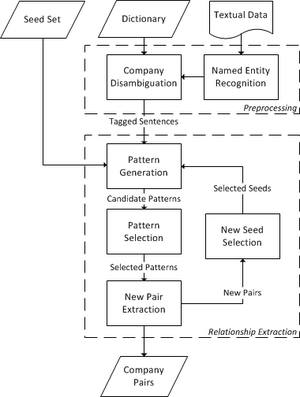
In this project, we want to extract the semantic business-relationships between companies, by analyzing web data sources, such as news articles, web sites of companies, and structured knowledge bases. Detecting business relationships has many commercial applications, for instance, risk-, market-, and competitor analysis. We are currently focused on relationship types, such as ownership_of, partnership_of, competitor_of, and supplier_of. Our final goal is to build a semantic graph.