Der letzte Schritt in einem Datenintegrationsprozess, nachdem Schemamatching und Duplikaterkennung durchgeführt worden sind, ist das Zusammenführen unterschiedlicher, sich u.U. widersprechender, Repräsentationen ein und desselben Objektes in eine einzige konsistente Repräsentation. Diesen Schritt bezeichnet man als Datenfusion. Er zielt darauf ab, die in den Attributwerten vorhandenen Unsicherheiten und Widersprüche zu entfernen.
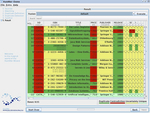
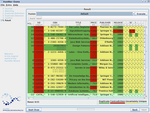
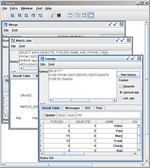
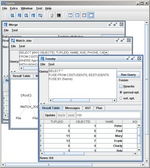
Im Rahmen des HumMer Systems wurde eine Datenfusionskomponente implementiert. Diese erlaubt es, spaltenweise Konfliktlösungsfunktionen auf Daten anzuwenden. Die Funktionen werden auf Gruppen von Tupeln angewendet, die jeweils ein Objekt repräsentieren. Am Ende wird dem Nutzer eine einzige, fusionierte, Repräsentation pro Objekt präsentiert. Die Fusionskomponente erlaubt es weiterhin durch Ausnutzung von Lineage-Information Konflikte in den Daten farblich hervorzuheben, wie auf dem Bild rechts zu sehen ist.
Weitere Informationen liefert die Webseite zum HumMer-Projekt.