1.
Repke, T., Krestel, R.: Extraction and Representation of Financial Entities from Text. In: Consoli, S., Reforgiato Recupero, D., en Saisana, M. (reds.) Data Science for Economics and Finance. bll. 241–263. Springer, Cham (2021).
In our modern society, almost all events, processes, and decisions in a corporation are documented by internal written communication, legal filings, or business and financial news. The valuable knowledge in such collections is not directly accessible by computers as they mostly consist of unstructured text. This chapter provides an overview of corpora commonly used in research and highlights related work and state-of-the-art approaches to extract and represent financial entities and relations.The second part of this chapter considers applications based on knowledge graphs of automatically extracted facts. Traditional information retrieval systems typically require the user to have prior knowledge of the data. Suitable visualization techniques can overcome this requirement and enable users to explore large sets of documents. Furthermore, data mining techniques can be used to enrich or filter knowledge graphs. This information can augment source documents and guide exploration processes. Systems for document exploration are tailored to specific tasks, such as investigative work in audits or legal discovery, monitoring compliance, or providing information in a retrieval system to support decisions.
2.
Schwanhold, R., Repke, T., Krestel, R.: Modeling the Evolution of Word Senses with Force-Directed Layouts of Co-occurrence Networks. Proceedings of the 2nd International Workshop on Computational Approaches to Historical Language Change (LChange@ACL 2021). 1–6 (2021).
Languages evolve over time and the meaning of words can shift. Furthermore, individual words can have multiple senses. However, existing language models typically only reflect one word sense per word and don't deal with semantic changes over time. While there are language models that can either model semantic change of words or multiple word senses, none of them cover both aspects simultaneously. We propose a novel force-directed graph layout algorithm to draw a network of frequently co-occurring words. In this way, we are able to use the drawn graph to visualize the evolution of word senses. In addition, we hope that jointly modeling semantic change and multiple senses of words results in improvements for the individual tasks.
3.
Risch, J., Repke, T., Kohlmeyer, L., Krestel, R.: ComEx: Comment Exploration on Online News Platforms. Joint Proceedings of the ACM IUI 2021 Workshops co-located with the 26th ACM Conference on Intelligent User Interfaces (IUI). bll. 1–7. CEUR-WS.org (2021).
The comment sections of online news platforms have shaped the way in which people express their opinion online. However, due to the overwhelming number of comments, no in-depth discussions emerge. To foster more interactive and engaging discussions, we propose our ComEx interface for the exploration of reader comments on online news platforms. Potential discussion participants can get a quick overview and are not discouraged by an abundance of comments. It is our goal to represent the discussion in a graph of comments that can be used in an interactive user interface for exploration. To this end, a processing pipeline fetches comments from several different platforms and adds edges in the graph based on topical similarity or meta-data and ranks nodes on metrics such as controversy or toxicity. By interacting with the graph, users can explore and react to single comments or entire threads they are interested in.
4.
Repke, T., Krestel, R.: Visualising Large Document Collections by Jointly Modeling Text and Network Structure. Proceedings of the Joint Conference on Digital Libraries (JCDL). (2020).
Many large text collections exhibit graph structures, either inherent to the content itself or encoded in the metadata of the individual documents. Example graphs extracted from document collections are co-author networks, citation networks, or named-entity-cooccurrence networks. Furthermore, social networks can be extracted from email corpora, tweets, or social media. When it comes to visualising these large corpora, either the textual content or the network graph are used. In this paper, we propose to incorporate both, text and graph, to not only visualise the semantic information encoded in the documents' content but also the relationships expressed by the inherent network structure. To this end, we introduce a novel algorithm based on multi-objective optimisation to jointly position embedded documents and graph nodes in a two-dimensional landscape. We illustrate the effectiveness of our approach with real-world datasets and show that we can capture the semantics of large document collections better than other visualisations based on either the content or the network information.
5.
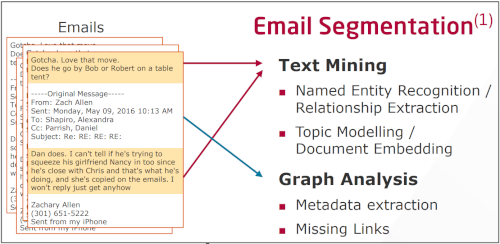
Repke, T., Krestel, R.: Bringing Back Structure to Free Text Email Conversations with Recurrent Neural Networks. 40th European Conference on Information Retrieval (ECIR 2018). Springer, Grenoble, France (2018).
Email communication plays an integral part of everybody's life nowadays. Especially for business emails, extracting and analysing these communication networks can reveal interesting patterns of processes and decision making within a company. Fraud detection is another application area where precise detection of communication networks is essential. In this paper we present an approach based on recurrent neural networks to untangle email threads originating from forward and reply behaviour. We further classify parts of emails into 2 or 5 zones to capture not only header and body information but also greetings and signatures. We show that our deep learning approach outperforms state-of-the-art systems based on traditional machine learning and hand-crafted rules. Besides using the well-known Enron email corpus for our experiments, we additionally created a new annotated email benchmark corpus from Apache mailing lists.