Schwanhold, R., Repke, T., Krestel, R. (2021) ‘Modeling the Evolution of Word Senses with Force-Directed Layouts of Co-occurrence Networks’, Proceedings of the 2nd International Workshop on Computational Approaches to Historical Language Change (LChange@ACL 2021), 1–6.
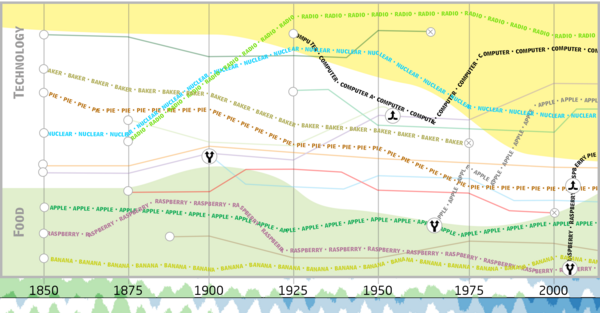
Languages evolve over time and the meaning of words can shift. Furthermore, individual words can have multiple senses. However, existing language models typically only reflect one word sense per word and don't deal with semantic changes over time. While there are language models that can either model semantic change of words or multiple word senses, none of them cover both aspects simultaneously. We propose a novel force-directed graph layout algorithm to draw a network of frequently co-occurring words. In this way, we are able to use the drawn graph to visualize the evolution of word senses. In addition, we hope that jointly modeling semantic change and multiple senses of words results in improvements for the individual tasks.
Ehmüller, J., Kohlmeyer, L., McKee, H., Paeschke, D., Repke, T., Krestel, R., Naumann, F. (2020) ‘Sense Tree: Discovery of New Word Senses with Graph-based Scoring’, in Proceedings of the Conference on "Lernen, Wissen, Daten, Analysen" (LWDA), 1–12.
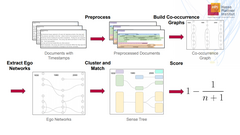
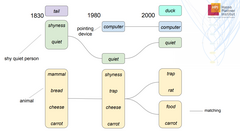
Language is dynamic and constantly evolving: both the us-age context and the meaning of words change over time. Identifying words that acquired new meanings and the point in time at which new word senses emerged is elementary for word sense disambiguation and entity linking in historical texts. For example, cloud once stood mostly for the weather phenomenon and only recently gained the new sense of cloud computing. We propose a clustering-based approach that computes sense trees, showing how meanings of words change over time. The produced results are easy to interpret and explain using a drill-down mechanism. We evaluate our approach qualitatively on the Corpus of Historic American English (COHA), which spans two hundred years.