Der IBM Information Server wird im Fachgebiet Informationssysteme bereits erfolgreich in Lehre und Forschung eingesetzt. Begleitend zu diesem Projekt werden zusätzliche Veranstaltungen, Workshops und Diskussionen stattfinden, zu denen die Teilnehmer des Bachelorprojekts herzlich eingeladen sind.
Die Teilnehmerzahl ist auf 8 Mitglieder beschränkt. Die technische Umsetzung erfolgt mit Java.
Projektbeschreibung
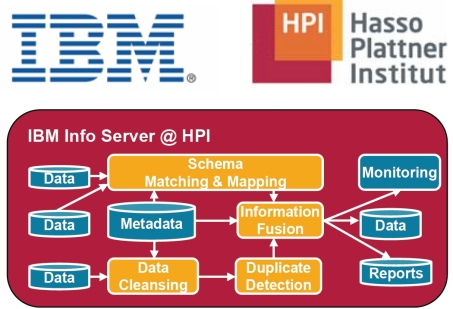
Der IBM Information Server umfasst bereits umfangreiche Funktionalitäten zum Verständnis, Bereinigen, Umwandeln und Bereitstellen unabhängiger, heterogener Daten aus verschiedenen Quellen. Ziel dieses Projektes ist es, den IBM Information Server um neue Methoden aus der Forschung, z.B. zur Duplikaterkennung, zu erweitern, die eine optimale Integration heterogener und autonomer Informationsquellen in verschiedensten Szenarien ermöglichen.
Zusätzlich unterstützt der IBM Information Server den Aufbau einer Service-orientierten Architektur (SOA), um implementierte Funktionalitäten als Integrationsservices in verschiedene Prozessen und Szenarien wiederverwenden zu können.
Es werden vom Fachgebiet Informationssysteme und IBM mehrere Integrationsszenarien (use cases) aus dem SAP Umfeld zur Verfügung gestellt, für die unter Verwendung des erweiterten IBM Information Servers ein konkretes Integrationssystem implementiert werden soll.
Projektvorbereitung
In der Vorbereitungsphase werden Grundlagen der Informationsintegration vorgestellt. Die Teilnehmer lernen Techniken der Informationsintegration und deren Optimierung kennen. Darüber hinaus werden Spezialthemen, etwa Methoden der Informationsqualität und Datenreinigung, der Informationssuche und des Metadatenmanagements behandelt. Diese Themen werden im Rahmen regelmäßiger Treffen sowohl theoretisch als auch praktisch in regelmäßigen Treffen im Wintersemester 2007/08 durch die Teilnehmer bearbeitet und vorgestellt. Detaillierte Kenntnisse zum Arbeiten mit dem IBM Information Server werden im Vorbereitungsseminar zusätzlich vermittelt und erste Methoden werden umgesetzt.
Projektbeginn: 15.10.2007
Raum: A 1.10
Kontakt
Für weiterführende Informationen stehen Prof. Dr. Felix Naumann und Alexander Albrecht zur Verfügung. Eine Terminabsprache ist über das Sekretariat von Prof. Naumann möglich: office-naumann(at)hpi.uni-potsdam.de
http://www.ibm.com/de/entwicklung/
http://www.ibm.com/software/de/db2/integration/