Detecting anomalous subsequences in time series data is an important task in many areas, ranging from manufacturing processes over finance applications to health care monitoring. An anomaly can indicate important events, such as production faults, delivery bottlenecks, systems defects, or heart flicker, and is, therefore, of central interest. Because time series are often large and exhibit complex patterns, data scientists have developed various specialized algorithms for the automatic detection of such anomalous patterns. Multivariate time series, which are time series with more than one channel (floating point value), are particularly challenging, as anomalous patterns can be found in any single channel and even combinations of channels. For this reason, anomaly detection in multivariate time series is very complex and comes, i.a., with the following challenges:
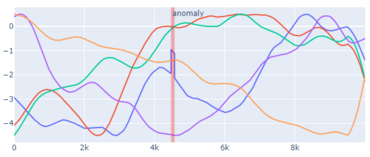
- Localization: Anomalies can appear in only a single channel (see Fig. 1), in multiple channels, and in all channels at the same time.
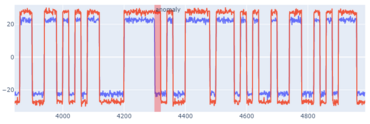
- Correlation: Anomalies can appear as correlation anomalies, in which all individual channels behave normally but some subset of channels is out-of-sync (see Fig. 2).
- Dimensionality: Due to the curse of dimensionality, anomalies become very hard to detect on multivarite datasets with many channels but only limited length.
- Complexity: Mutlivariate time series are not only long (high number of data points), but also wide (high number of channels/dimensions), which in many cases leads to huge amounts of data that need to be processed within certain time and memory limits.
Most existing solutions fail in at least one of these challenges. In the seminar, we will consider certain multivariate datasets from one of our industry partners, for which most anomaly detection algorithms struggle to find any, let alone the desired, anomalies. This shows that existing multivariate anomaly detection approaches must be improved further to overcome the mentioned challenges. Our goal is, therefore, to beat all these challenges at the same time and present one (or multiple) algorithms that are truely useful in practice.