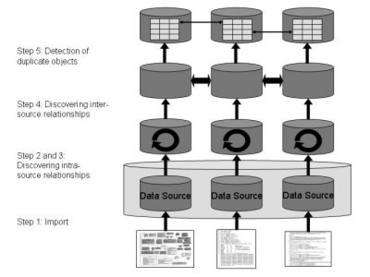
The proposed integration process consists of five steps that can be seen in the upper figure: In the first step, the data source that is to be integrated has to be imported into relational format. Referring to the Life Sciences application domain, our experience has shown that there exist publicly available import methods for almost all known data sources. In other cases, a quick-and-dirty parser is sufficient for Aladin to use.
The second and third step identify the primary relation and the secondary relations: First, we look for attributes that could serve as accession numbers. This means (following our experiences), their values are at least four characters long, contain at least one character, and must not differ in length more than 20%. Second, we search the data for unary inclusion dependencies (see Spider algorithm) to utilize them (after applying some filtering heuristics) as foreign keys.
We identify a relation as primary relation if (i) it contains an accession number candidate and (ii) the number of INDs referencing any attribute in this relation is maximal in comparison to other relations. All non-primary relations are identified as secondary relation.
Whereas the three preceding steps take place within only one source at a time (intra-source), we finally concentrate on the inter-source level in the fourth and fifth step. This way, we can find cross-references to objects in other data sources and duplicates, i.e., objects representing the same real world object, respectively. Enabling us to filter redundant information and to combine complementary one, these steps conclude the integration process.