Team: Jan Ehmüller, Lasse Kohlmeyer, Holly McKee, Daniel Paeschke
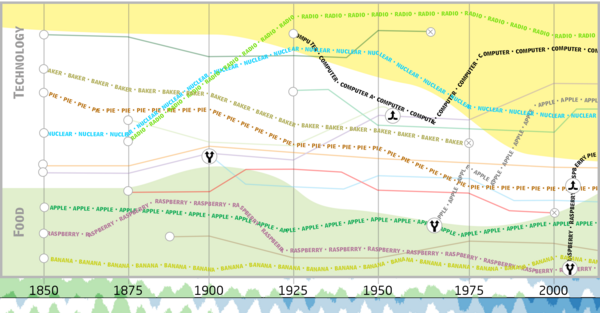
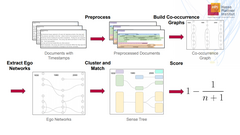
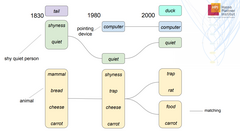
As language evolves, a word can gain new senses. For instance, the word “cloud” was once only used in the newspaper section of weather forecasts. Nowadays, it is increasingly used in the context of “Cloud Computing”. In this master’s project, we develop a novel approach that represents the usage of words over time as a graph. We address the following research question: How can we identify words with new senses? We develop an approach to rank the likelihood that one word gained a new sense over the last 200 years. Our approach was applied to the “Corpus of Historical American English” (COHA).
To learn more, watch our 13min Presentation Video.