The scientists from the Information Systems research group use articles and reader comments from various online newspapers for their analyses. These include British news sites, such as “The Guardian” and “The Telegraph,” and the American sites “The Washington Post” and “Fox News.” In German-speaking countries, researchers use online articles and readers’ comments from ZEIT ONLINE. The data collected in the process allows for a precise analysis of the comments and shows the change of comment behavior and moderation effort over time.
With the help of variables linked with each comment, different aspects can be evaluated, including opinion tonality (e.g., research on hate speech), gender differences or the topics themselves. In the first step of their research, Krestel and Risch concentrate on predicting the volume of comments editorial staff can expect after an article is published. Moderators of journalistic online media should thereby be able to estimate the effort for interaction with users and better be able to plan ahead.
“Our goal is to identify the top 10 percent of articles discussed every week,” says Krestel. To satisfy this objective, the team includes the metadata of the article, the contextual information, the title and also the text of the article itself. “For the evaluation we primarily use decision trees and statistical regression models. While great strides have been made in the field of neural networks, editors not only need a reliable predication but also a justification of what factors contribute strongly or very strongly to that prediction,” Krestel points out.
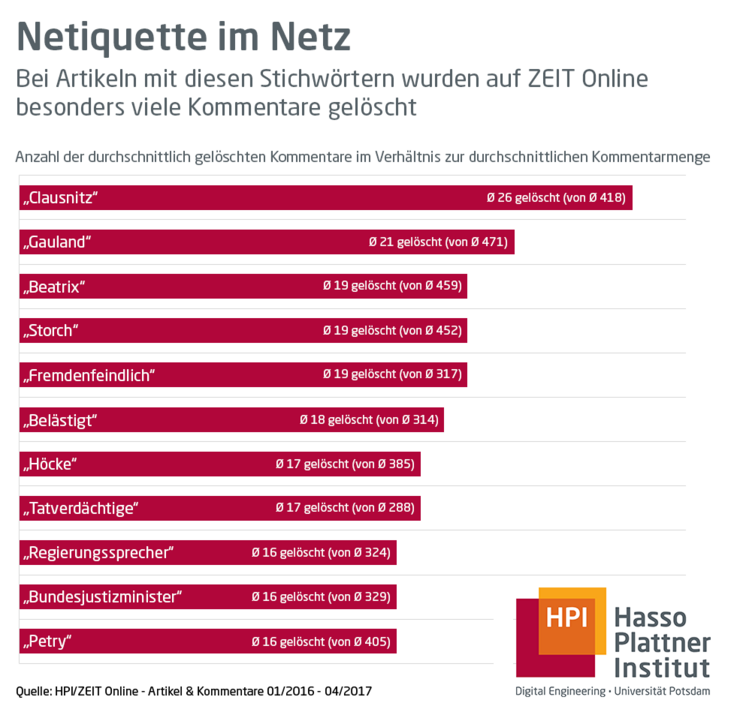
According to the calculations of HPI researchers, determining factors for the expected number of comments are, in particular, the words contained in the article (a bag-of-words model was used), the superordinate topic of an article (via topic modeling) the key words in the title (n-grams or words groups consisting of 1-3 words and keywords provided by the author of the article), as well as the metadata of the article (among them, the source and the resource). Thus, Krestel and Risch could determine that articles, in the period examined, containing the terms “Clausnitz,” “Gauland,” “Beatrix” and “Storch,” had comments most likely to violate the netiquette at ZEIT ONLINE. These comments did not raise objections based on the terms per se, but because of irregularities that overstepped boundaries in terms of formulations (insulting or discriminatory) in the comment text.
“We were able to evaluate which topics lead to high or low levels of comments that have violated the netiquette according to the moderators," says HPI PhD student Risch. For instance, in articles containing the term "Clausnitz" on the average every sixteenth comment had to be deleted; for articles with the term "CO2" about every hundred and nineteenth comment violated the rules. “Based on this data, we can see, for example, which topics are causing discussions to get out of hand. In this sense, the analysis is also a testimony to the culture of debate within a specific period," says Risch.