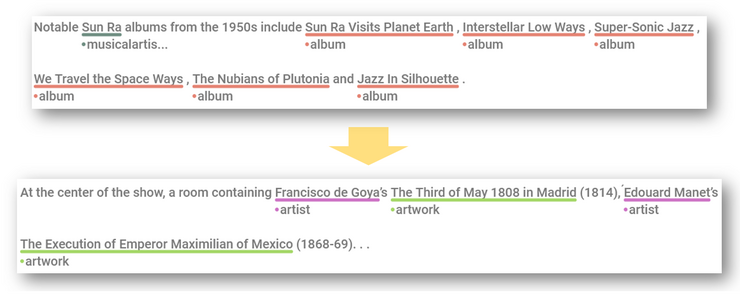
My research focuses mainly on the adaptation of natural language processing (NLP) techniques to domain-specific scenarios, where the general-domain models fail to deliver satisfactory results or the availability of labeled data is not guaranteed. In particular, I am interested in introducing domain-specific knowledge into NLP models, to improve their ability to represent knowledge.
In particular, the following NLP tasks are of my interest:
- Few-Shot Named Entity Recognition
- Nested Named Entity Recognition
- Open Information Extraction
- Injecting knowledge into language models
Additionally, I am interested in complementing the NLP tasks with the analysis of other data sources like pictures or accompanying images. Specially, I intend to combine the analysis of both text and images in art-historic documents, where the pictorial representation of the artwork is accompanied by textual descriptions. In such documents, the combination of computer vision techniques like vision transformers and NLP techniques like language modeling and information extraction could benefit from each other to produce meaningful representations for downstream tasks like information retrieval and knowledge graph construction.