Berger, Julian; Bleidt, Tibor; Büßemeyer, Martin; Ding, Marcus; Feldmann, Moritz; Feuerpfeil, Moritz; Jacoby, Janusch; Schröter, Valentin; Sievers, Bjarne; Spranger, Moritz; Stadlinger, Simon; Wullenweber, Paul; Cohen, Sarel; Doskoč, Vanja; Friedrich, Tobias Fine-Grained Localization, Classification and Segmentation of Lungs with Various DiseasesCVPR Workshop on Fine-Grained Visual Categorization (FGVC@CVPR) 2021
The fine-grained localization and classification of various lung abnormalities is a challenging yet important task for combating diseases and, also, pandemics. In this paper, we present one way to detect and classify abnormalities within chest X-ray scans. In particular, we investigate the use of binary image classification (to distinguish between healthy and infected chests) and the weighted box fusion (which constructs a detection box using the proposed boxes within range). We observe that both methods increase the performance of a base model significantly. Furthermore, we improve state of the art on lung segmentation, even in the presence of abnormalities. We do so using transfer learning to fine-tune a UNet model on the Montgomery and Shenzhen datasets. In our experiments, we compare standard augmentations (like crop, pad, rotate, warp, zoom, brightness, and contrast variations) to more complex ones (for example, block masking and diffused noise augmentations). This way, we obtain a state-of-the-art model with a dice score of 97.9%. In particular, we show that simple augmentations outperform complex ones in our setting.
Doskoč, Vanja; Kötzing, Timo Normal Forms for Semantically Witness-Based Learners in Inductive InferenceComputability in Europe (CiE) 2021: 158–168
In \emph{inductive inference, we study learners (computable devices) inferring formal languages. In particular, we consider \emph{semantically witness-based learners, that is, learners which are required to \emph{justify each of their semantic mind changes. This natural requirement deserves special attention as it is a specialization of various important learning paradigms. As such, it has already proven to be fruitful for gaining knowledge about other types of restrictions. In this paper, we provide a thorough analysis of semantically converging, semantically witness-based learners, obtaining \emph{normal forms for them. Most notably, we show that \emph{set-driven globally semantically witness-based learners are equally powerful as their \emph{Gold-style semantically conservative counterpart. Such results are key to understanding the, yet undiscovered, mutual relation between various important learning paradigms of semantically converging learners.
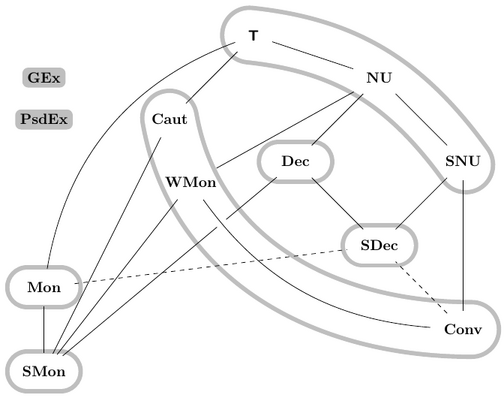
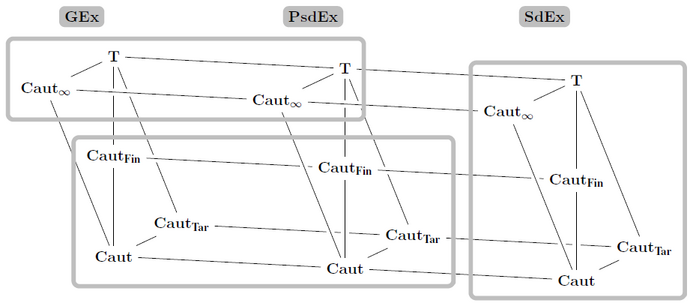
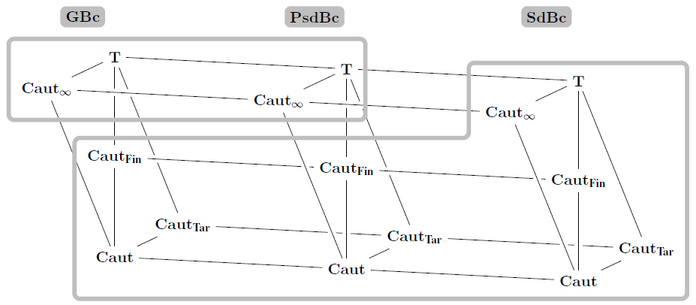
Doskoč, Vanja; Kötzing, Timo Mapping Monotonic Restrictions in Inductive InferenceComputability in Europe (CiE) 2021: 146–157
In \emph{inductive inference we investigate computable devices (learners) learning formal languages. In this work, we focus on \emph{monotonic learners which, despite their natural motivation, exhibit peculiar behaviour. A recent study analysed the learning capabilities of \emph{strongly monotone learners in various settings. The therein unveiled differences between \emph{explanatory (syntactically converging) and \emph{behaviourally correct (semantically converging) such learners motivate our studies of \emph{monotone learners in the same settings. While the structure of the pairwise relations for monotone explanatory learning is similar to the strongly monotone case (and for similar reasons), for behaviourally correct learning a very different picture emerges. In the latter setup, we provide a \emph{self-learning class of languages showing that monotone learners, as opposed to their strongly monotone counterpart, do heavily rely on the order in which the information is given, an unusual result for behaviourally correct learners.
Berger, Julian; Böther, Maximilian; Doskoč, Vanja; Gadea Harder, Jonathan; Klodt, Nicolas; Kötzing, Timo; Lötzsch, Winfried; Peters, Jannik; Schiller, Leon; Seifert, Lars; Wells, Armin; Wietheger, Simon Learning Languages with Decidable HypothesesComputability in Europe (CiE) 2021: 25–37
In \emph{language learning in the limit, the most common type of hypothesis is to give an enumerator for a language, a \(W\)-index. These hypotheses have the drawback that even the membership problem is undecidable. In this paper, we use a different system which allows for naming arbitrary decidable languages, namely \emph{programs for characteristic functions (called \(C\)-indices). These indices have the drawback that it is now not decidable whether a given hypothesis is even a legal \(C\)-index. In this first analysis of learning with \(C\)-indices, we give a structured account of the learning power of various restrictions employing \(C\)-indices, also when compared with \(W\)-indices. We establish a hierarchy of learning power depending on whether \(C\)-indices are required (a) on all outputs; (b) only on outputs relevant for the class to be learned or (c) only in the limit as final, correct hypotheses. We analyze all these questions also in relation to the mode of data presentation. Finally, we also ask about the relation of semantic versus syntactic convergence and derive the map of pairwise relations for these two kinds of convergence coupled with various forms of data presentation.
Kißig, Otto; Taraz, Martin; Cohen, Sarel; Doskoč, Vanja; Friedrich, Tobias Drug Repurposing for Multiple COVID Strains using Collaborative FilteringICLR Workshop on Machine Learning for Preventing and Combating Pandemics (MLPCP@ICLR) 2021
The ongoing COVID-19 pandemic demands for a swift discovery of suitable treatments. The development of completely new compounds for such a novel disease is a challenging, time intensive process. This amplifies the relevance of drug repurposing, a technique where existing drugs are used to treat other diseases. A common bioinformatical approach to this is based on knowledge graphs, which compile relationships between drugs, diseases, genes and other biomedical entities. Then, graph neural networks (GNNs) are used for the drug repurposing task as they provide a good link prediction performance on such knowledge graphs. Building on state-of-the-art GNN research, Doshi & Chepuri (2020) construct the remarkable model DR-COVID. We re-implement their model and extend the approach to perform significantly better. We propose and evaluate several strategies for the aggregation of link predictions into drug recommendation rankings. With the help of clustering of similar target diseases we improve the model by a substantial margin, compiling a top-100 ranking of candidates including 32 currently being in COVID-19-related clinical trials. Regarding the re-implementation, we offer more flexibility in the selection of the graph neighborhood sizes fed into the model and reduce the training time significantly by making use of data parallelism.
Quinzan, Francesco; Doskoč, Vanja; Göbel, Andreas; Friedrich, Tobias Adaptive Sampling for Fast Constrained Maximization of Submodular FunctionsArtificial Intelligence and Statistics (AISTATS) 2021: 964–972
Several large-scale machine learning tasks, such as data summarization, can be approached by maximizing functions that satisfy submodularity. These optimization problems often involve complex side constraints, imposed by the underlying application. In this paper, we develop an algorithm with poly-logarithmic adaptivity for non-monotone submodular maximization under general side constraints. The adaptive complexity of a problem is the minimal number of sequential rounds required to achieve the objective. Our algorithm is suitable to maximize a non-monotone submodular function under a \(p\)-system side constraint, and it achieves a \((p + O({\sqrt{p}}))\)-approximation for this problem, after only poly-logarithmic adaptive rounds and polynomial queries to the valuation oracle function. Furthermore, our algorithm achieves a \(p + O(1))\)-approximation when the given side constraint is a \(p\)-extendible system. This algorithm yields an exponential speed-up, with respect to the adaptivity, over any other known constant-factor approximation algorithm for this problem. It also competes with previous known results in terms of the query complexity. We perform various experiments on various real-world applications. We find that, in comparison with commonly used heuristics, our algorithm performs better on these instances.